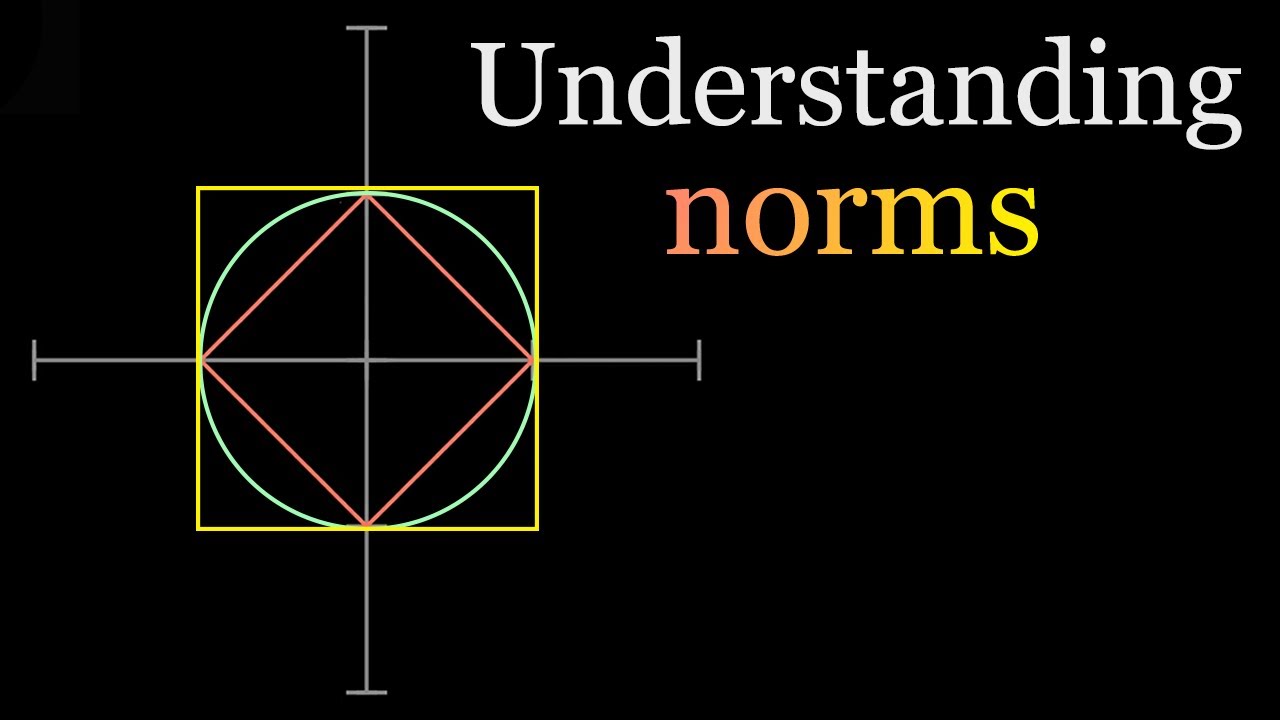
The L1 norm that is calculated as the sum of the absolute values of the vector. … The L2 norm that is calculated as the square root of the sum of the squared vector values. The max norm that is calculated as the maximum vector values.
- Q. What is the use of validation set?
- Q. What is cross validation set?
- Q. Why is L1 norm not differentiable?
- Q. What is L1 and L2 regularization What are the differences between the two?
- Q. Is lasso L1 or L2?
- Q. What is L2 regularization in deep learning?
- Q. What is L2 penalty?
- Q. What does L2 regularization do?
- Q. Is elastic net better than Lasso?
- Q. Why is it called ridge regression?
- Q. Is ridge regression biased?
- Q. What is the difference between ridge regression and Lasso?
- Q. What is regularization in machine learning?
Q. What is the use of validation set?
– Validation set: A set of examples used to tune the parameters of a classifier, for example to choose the number of hidden units in a neural network. – Test set: A set of examples used only to assess the performance of a fully-specified classifier. These are the recommended definitions and usages of the terms.
Q. What is cross validation set?
Cross-Validation set (20% of the original data set): This data set is used to compare the performances of the prediction algorithms that were created based on the training set. We choose the algorithm that has the best performance.
Q. Why is L1 norm not differentiable?
1 Answer. consider the simple case of a one dimensional w, then the L1 norm is simply the absolute value. The absolute value is not differentiable at the origin because it has a “kink” (the derivative from the left does not equal the derivative from the right).
Q. What is L1 and L2 regularization What are the differences between the two?
The main intuitive difference between the L1 and L2 regularization is that L1 regularization tries to estimate the median of the data while the L2 regularization tries to estimate the mean of the data to avoid overfitting. … That value will also be the median of the data distribution mathematically.
Q. Is lasso L1 or L2?
A regression model that uses L1 regularization technique is called Lasso Regression and model which uses L2 is called Ridge Regression. The key difference between these two is the penalty term. Ridge regression adds “squared magnitude” of coefficient as penalty term to the loss function.
Q. What is L2 regularization in deep learning?
It is the hyperparameter whose value is optimized for better results. L2 regularization is also known as weight decay as it forces the weights to decay towards zero (but not exactly zero). In L1, we have: In this, we penalize the absolute value of the weights. Unlike L2, the weights may be reduced to zero here.
Q. What is L2 penalty?
Penalty Terms Regularization works by biasing data towards particular values (such as small values near zero). … L2 regularization adds an L2 penalty equal to the square of the magnitude of coefficients. L2 will not yield sparse models and all coefficients are shrunk by the same factor (none are eliminated).
Q. What does L2 regularization do?
Therefore, the idea behind L2 regularization is to try to reduce model overfitting by keeping the magnitudes of the weight values small. Briefly, L2 regularization works by adding a term to the error function used by the training algorithm. The additional term penalizes large weight values.
Q. Is elastic net better than Lasso?
Lasso will eliminate many features, and reduce overfitting in your linear model. … Elastic Net combines feature elimination from Lasso and feature coefficient reduction from the Ridge model to improve your model’s predictions.
Q. Why is it called ridge regression?
Ridge regression adds a ridge parameter (k), of the identity matrix to the cross product matrix, forming a new matrix (X`X + kI). It’s called ridge regression because the diagonal of ones in the correlation matrix can be described as a ridge.
Q. Is ridge regression biased?
Ridge regression is a term used to refer to a linear regression model whose coefficients are not estimated by ordinary least squares (OLS), but by an estimator, called ridge estimator, that is biased but has lower variance than the OLS estimator.
Q. What is the difference between ridge regression and Lasso?
Lasso regression stands for Least Absolute Shrinkage and Selection Operator. … The difference between ridge and lasso regression is that it tends to make coefficients to absolute zero as compared to Ridge which never sets the value of coefficient to absolute zero.
Q. What is regularization in machine learning?
The regularization term, or penalty, imposes a cost on the optimization function for overfitting the function or to find an optimal solution. In machine learning, regularization is any modification one makes to a learning algorithm that is intended to reduce its generalization error but not its training error.
Norms are a very useful concept in machine learning. In this video, I've explained them with visual examples.#machinelearning #datascienceFor more videos ple…
No Comments